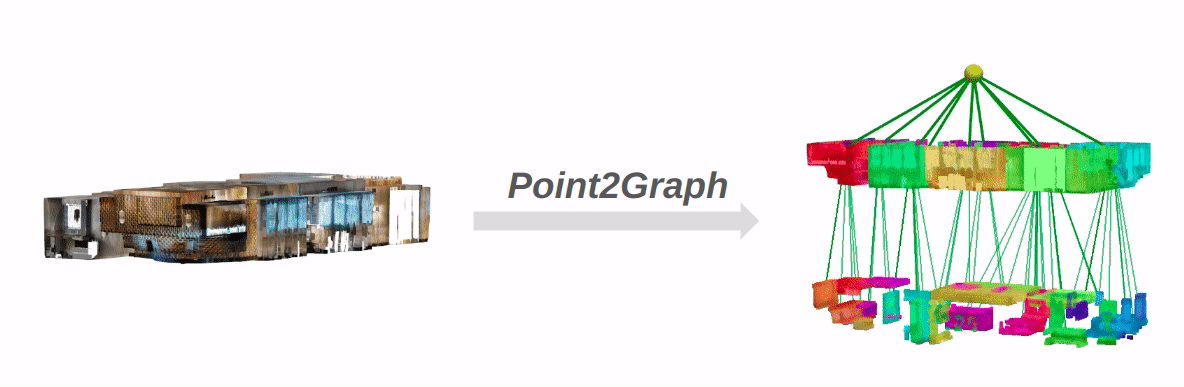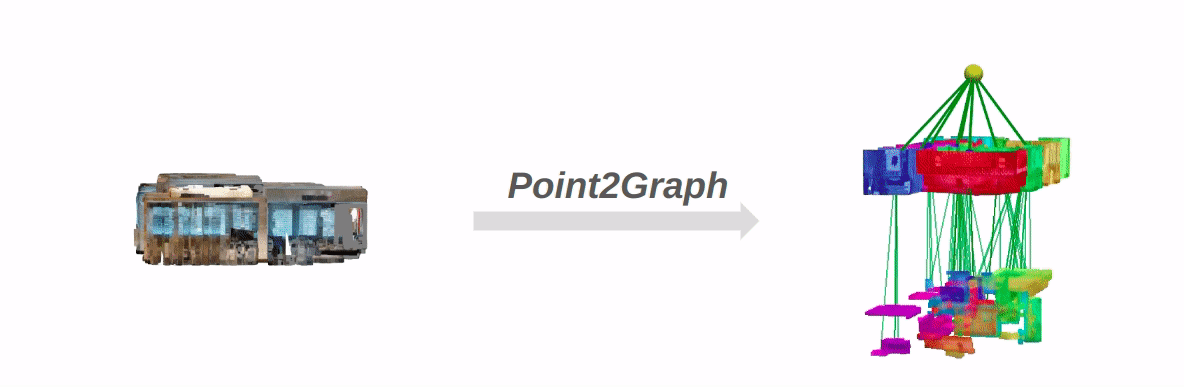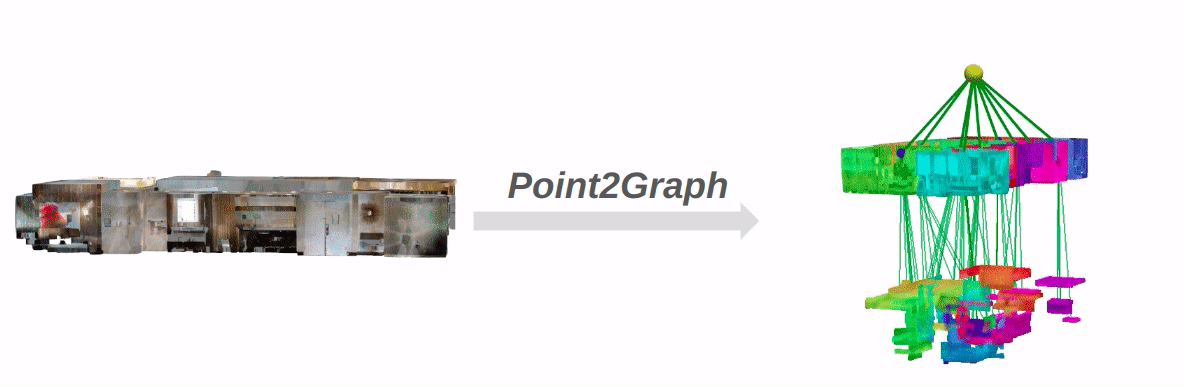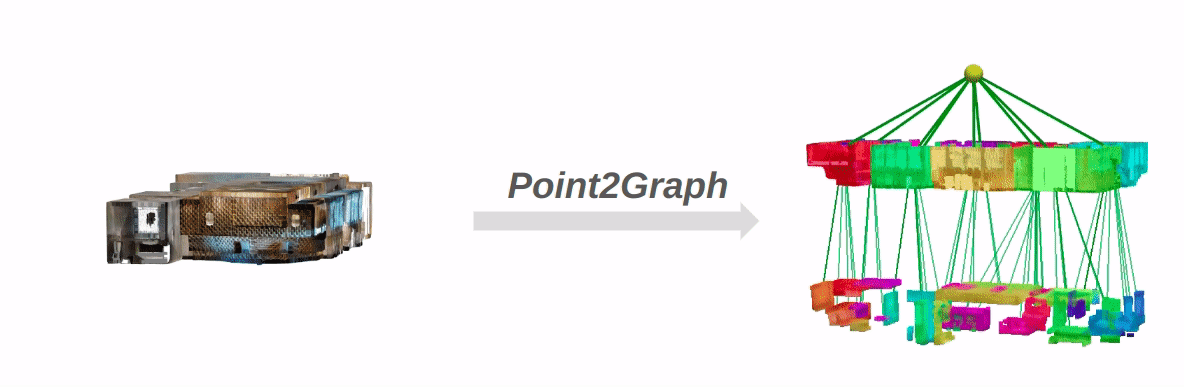
Current open-vocabulary scene graph generation algorithms highly rely on both 3D scene point cloud data and posed RGB-D images, which is limited in scenarios where RGB-D images or camera poses are not readily available. To solve this problem, we propose Point2Graph, a novel end-to-end point cloud-based 3D open-vocabulary scene graph generation framework in which the requirement of posed RGB-D image series is eliminated. This hierarchical framework contains room and object detection/segmentation and open-vocabulary classification. For the room layer, we leverage the advantage of merging the geometry-based border detection algorithm with the learning-based region detection to segment rooms and create a “Snap-Lookup” framework for open-vocabulary room classification. Besides, we create an end-to-end pipeline for the object layer to detect and classify 3D objects based solely on 3D point cloud data. Our evaluation result shows our framework can outperform the current state-of-the-art (SOTA) open-vocabulary object and room segmentation and classification algorithm on widely used real scene datasets.
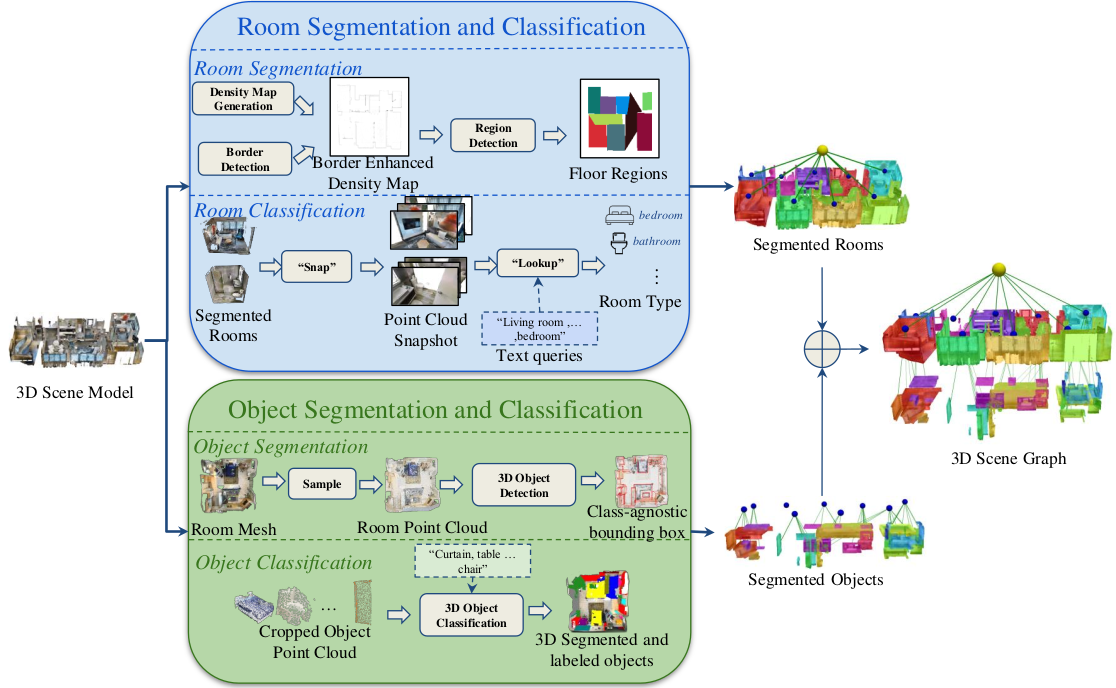
The overall pipeline of Point2Graph: The system is divided into two levels: the room level and the object level.
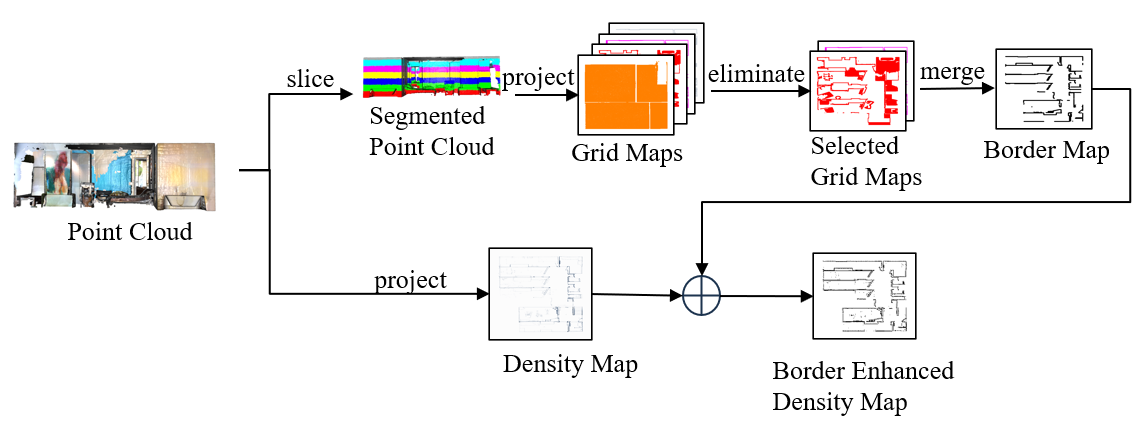
The process begins by segmenting the point cloud into N layers, each of which is projected into a grid map. Layers that do not meet specific criteria are eliminated. The remaining valid layers are then merged to form the border, which is combined with the original density map to create a border-enhanced density map.
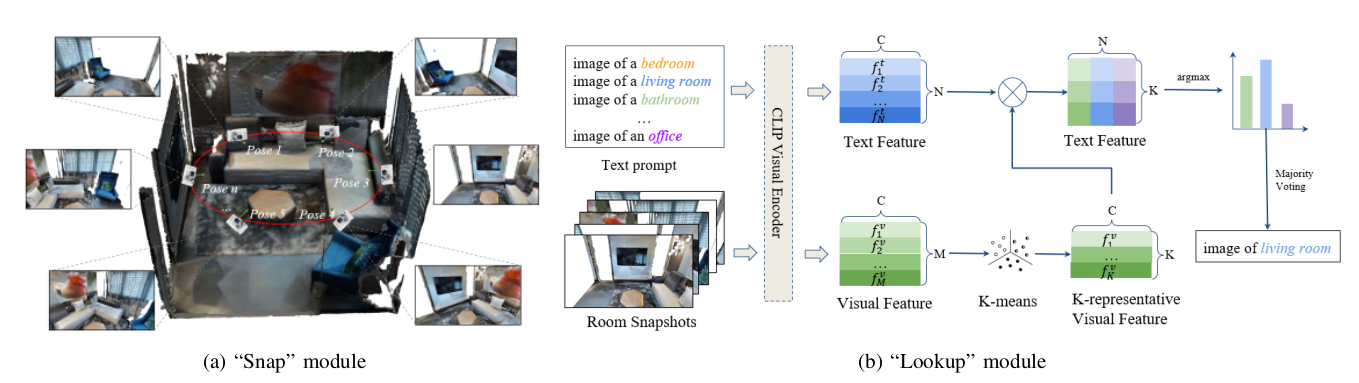
In “Snap” module, cameras are positioned evenly at the ellipse shape trajectory facing to the center of the room and snapshot the room from different positions. In the “Lookup” module, we associate each room with open-vocabulary embeddings extracted from K-representative CLIP features. Then, argmax and majority voting are applied to get the type for each room.
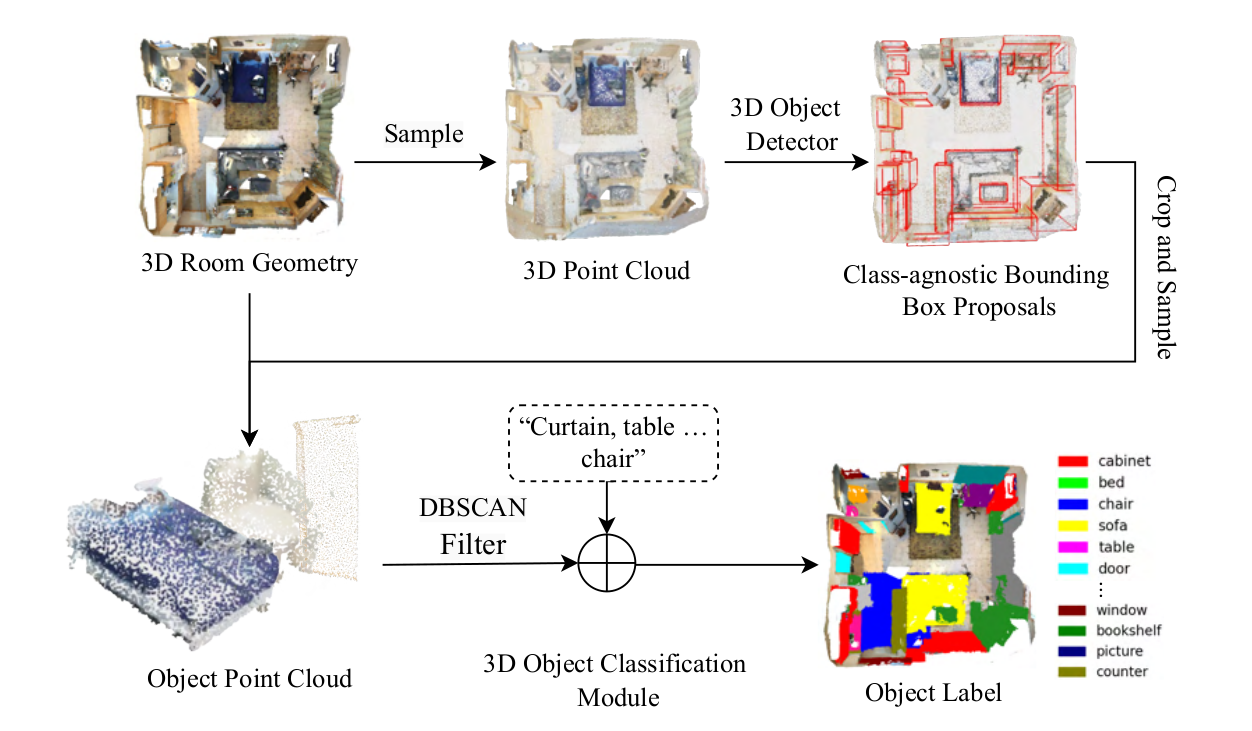
It consists of two stages: (1) detection and localization using class-agnostic bounding boxes and DBSCAN filtering for object refinement, and (2) classification via cross-modal retrieval, connecting 3D point cloud data with textual descriptions, without requiring annotations or RGB-D alignment.
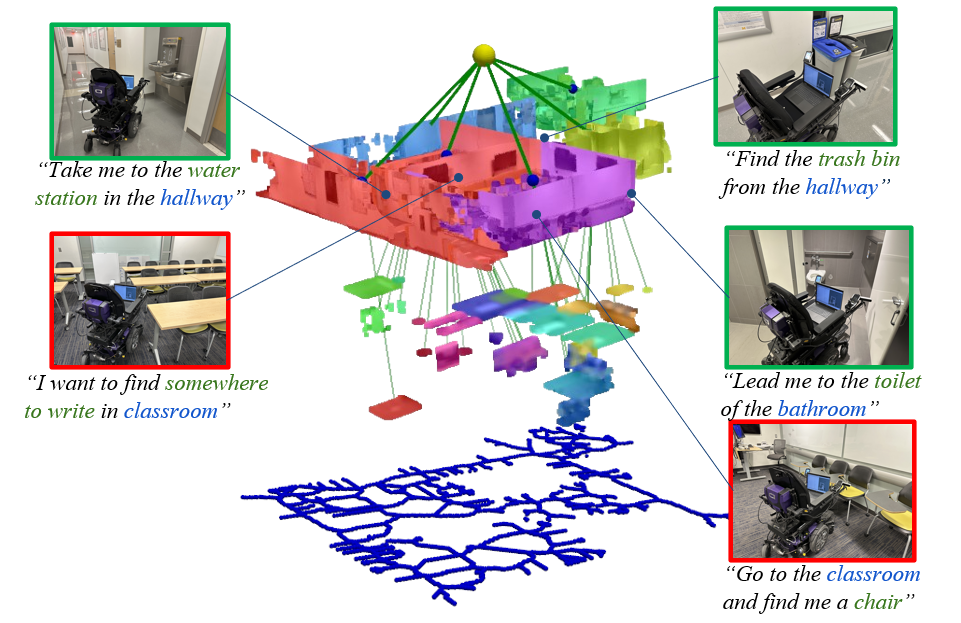
We construct the 3D open-vocabulary scene graph using Point2Graph algorithm and construct the Voronoi navigation graph. Then we conduct navigation tests in this environment.
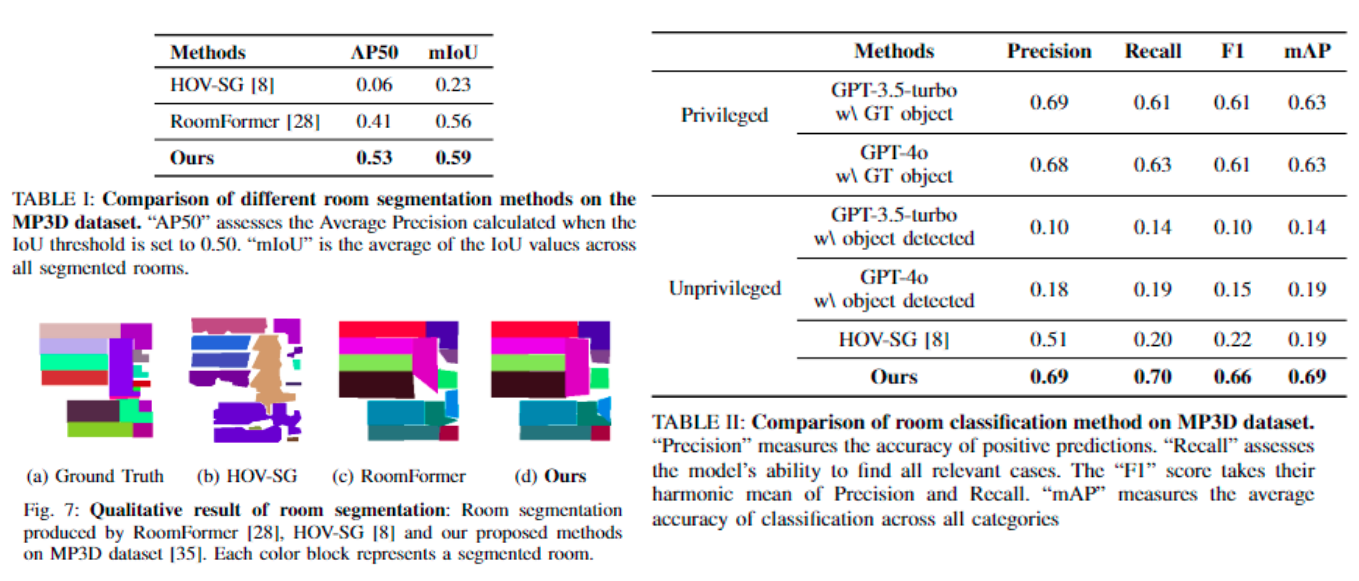
We evaluate our proposed room level segmentation method and classification method and evaluate it in Matterport3D dataset.
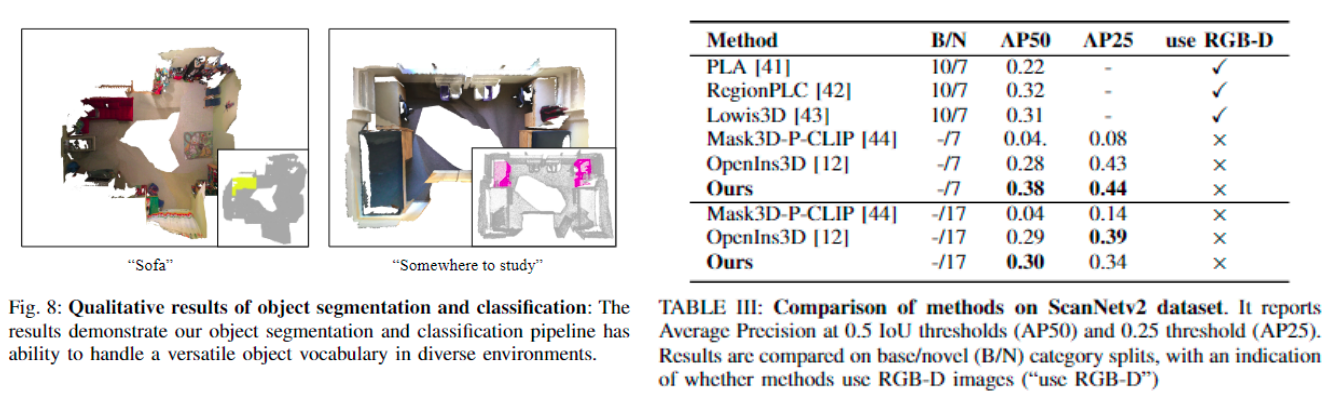
We evaluate our proposed object level segmentation method and classification method and evaluate it in ScanNetv2 dataset.
@misc{xu2024point2graphendtoendpointcloudbased,
title={Point2Graph: An End-to-end Point Cloud-based 3D Open-Vocabulary Scene Graph for Robot Navigation},
author={Yifan Xu and Ziming Luo and Qianwei Wang and Vineet Kamat and Carol Menassa},
year={2024},
eprint={2409.10350},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2409.10350},
}